

Unlocking the next wave of value creation with data operating systems
The development of operating systems caused huge amounts of value to accrue to the OS layer. Data operating systems will unlock a new wave of value creation by mapping & coordinating complex systems

There isn’t really much insight in this essay beyond discussing the type of businesses I’m interested in and excited by. As single-point SaaS products get more saturated, there is a lot of opportunity for data operating systems that enable users to map and manage the complex systems they engage with, so get in touch if you’re building in this space.
An operating system abstracts away the underlying hardware of a computer into a unified system that apps can easily interact with. It mediates and standardises the interactions between apps and hardware. Data operating systems will do the same for the interactions between apps and underlying data. They will create unified data layers that apps can easily interact with.
Just like the development of operating systems unlocked a new era of computing, with huge value accruing to the OS layer, data operating systems will unlock a new era of software and value accrual, particularly as single-point SaaS products get more and more saturated. While there are a number of “operating systems” in software at the moment, few are set up to become the defining OS layer in their respective industries and functions.
The impact of OS/360 and other operating systems
While it may seem alien to us now that we have supercomputers in our pockets, when computing first kicked off, we used to use mainframe computers. These behemoths took up entire rooms and were complex to use. Before operating systems were developed, to interact with these computers you had to:
Build custom apps for each computer/piece of hardware you use, with apps interacting with the hardware directly. App development was therefore hardware dependent. If you wanted to use different hardware, the app had to change as well
Interact with the hardware through specific apps to initiate their specific workflow
Communicate across siloed apps that were incredibly difficult to move data between
Operating systems abstracted that complexity away. Hardware plugged into the operating system and programs sat on top. Following the development of IBM’s OS/360 in 1964, the first major operating system, users were able to:
Build apps for the operating system, not the underlying computer, so it didn’t matter what hardware was used
Interact directly with the operating system to initiate multiple apps and workflows
Have a coherent view of the underlying hardware (abstracted away by the operating system) that the apps interacted with via the OS rather than directly
Communicate between apps seamlessly as all apps work from the same underlying operating system
The operating system unlocked huge value. Not only did it make software development significantly easier and more stable; at the same time, value accrued to the operating system layer while competition increased within the hardware and app layers, eroding their value as they became commoditised.
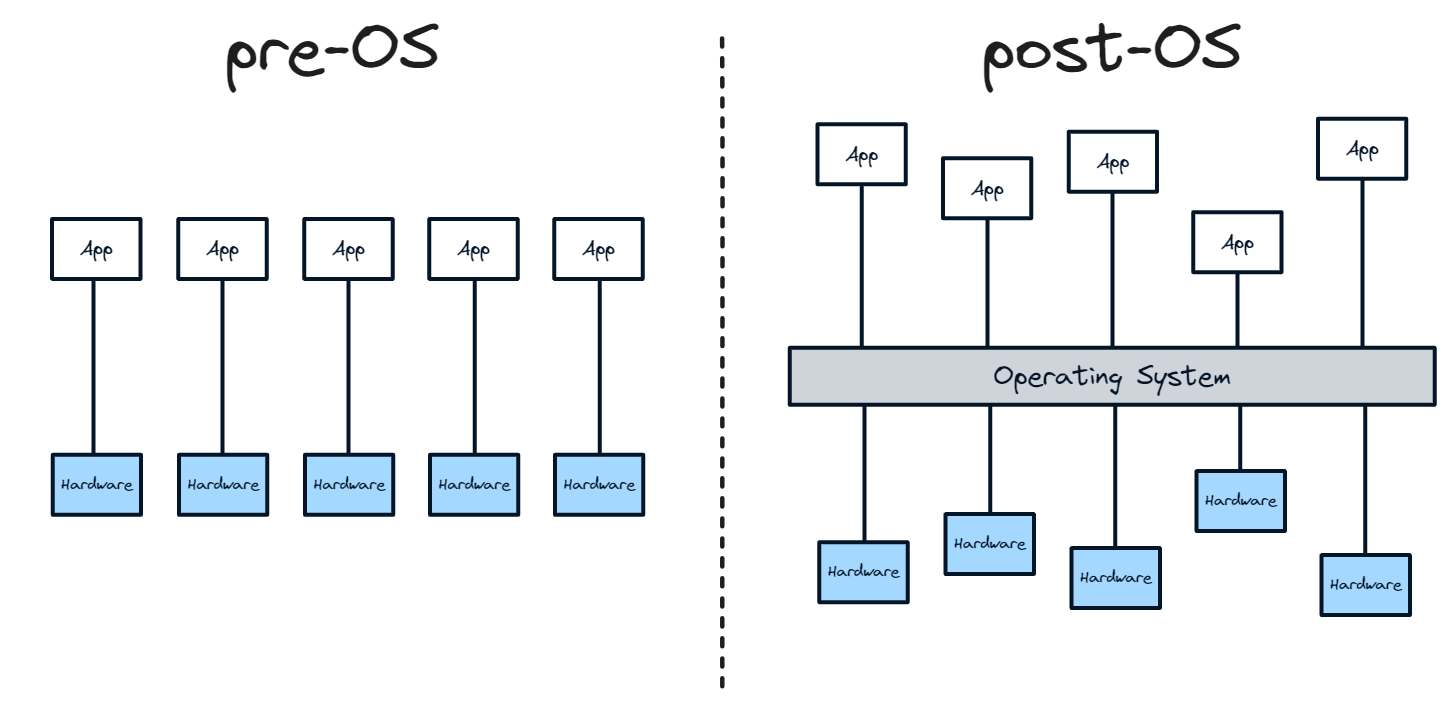
Software is predominantly in a pre-operating system era
In the “Software is eating the world era”, data is the new hardware. Just like we used to interact directly with the underlying hardware, the software we use today interacts directly with the underlying dataset. The front-end app is tightly integrated with the back-end database and is bespoke to that data source. If the data source changes slightly, the integration with the front-end has to be changed too. In my view, software is in a pre-OS era.
Currently, when we interact with software, we:
Build custom apps for each data source we use, with apps interacting with the data directly. App development is therefore data dependent. If we want to use a different data source or data structure, the app needs to change as well
Interact with the data through specific apps to initiate their specific workflow
Communicate across siloed apps that are hard to move data between
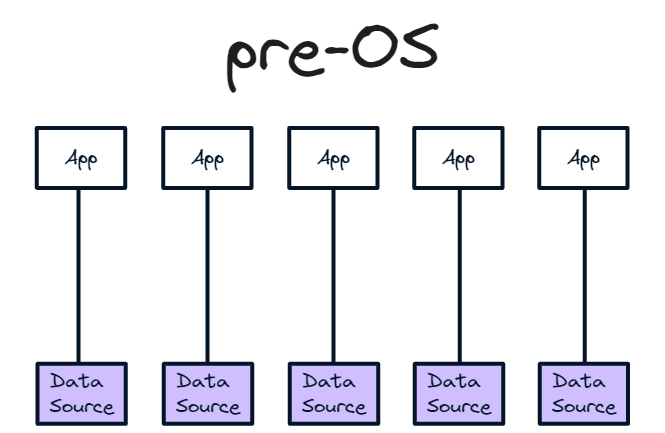
Now, technology makes this comparison imperfect. Obviously using multiple software products is easier than loading multiple programs into a mainframe computer or using different computers for different tasks, but the general theme still stands. We interact directly with data through the app rather than through an operating system. Each product typically builds its own dataset so if you want to change the dataset you need to change the product. And if we want to use multiple apps, porting data between them is a painful, and often manual, experience. If the products are relying on each other for input data to make decisions, this can also lead to inaccurate data - if you change something somewhere, it doesn’t necessarily mean it gets changed everywhere. APIs help but the experience is still like pre-OS days where we spend our time interacting with the underlying hardware, or in this case data, through apps.
Pre-OS products are hindering our ability to accurately map and understand systems
Pre-OS products mean understanding things at a system level is hard. For me, a system is anything that has multiple components. This can be everything from onboarding journeys and customer interactions, all the way up to macro-level financial and energy grid systems. We typically have separate products and data sources for each component of a system but getting an overall view at the system level is a challenge.
This has a number of consequences. Since it’s hard to move data between products and each app uses a different data source, there is no single view of everything going on in a system. There is no coherent view of all the underlying data. This makes understanding and coordinating the system difficult.
Perhaps it’s easiest to explain with an example. Take the supply chain of your average retailer. At a basic level, they have four core pieces of software needed to understand what is going on in their supply chain. (Yes, some components are missing but this is an analogy. With even more components it gets even messier)
Procurement management
What have they ordered from their suppliers, when will it arrive at the warehouse and how much will arrive. I organise anything that involves managing my vendors through this app/data source
Warehouse management
What is in the warehouse, where in the warehouse is it etc. I organise anything that involves managing my warehouse through this app/data source
Sales management
What will be leaving the warehouse, when will it leave and which customers will receive it. I organise anything that involves managing my sales through this app/data source
Returns management
What will be coming back to the warehouse, when will it arrive and how much stock will be returned. I organise anything that involves managing my returns through this app/data source
As a retailer, I want to understand and coordinate my supply chain and run workflows off the back of this information. I want to know what is going on across these four systems so I have a complete picture and can make informed decisions. However, getting these disparate products to talk so I have a coherent understanding of, for example, my stock levels - and can initiate the relevant workflows based on that data - is a pain. Sure I can link them via APIs but if I want to change a data source or use a different provider, I have to reintegrate them. Equally, the data in different products may not agree and I don’t know which version is correct. I am spending time in four different apps with no single view of what exactly is going on. I might port some data into a dashboard manually or via an API to create a rudimentary OS but it’s not a great experience. Life would be a lot easier if all my different data sources and products were connected into one operating system that mapped and coordinated my supply chain.
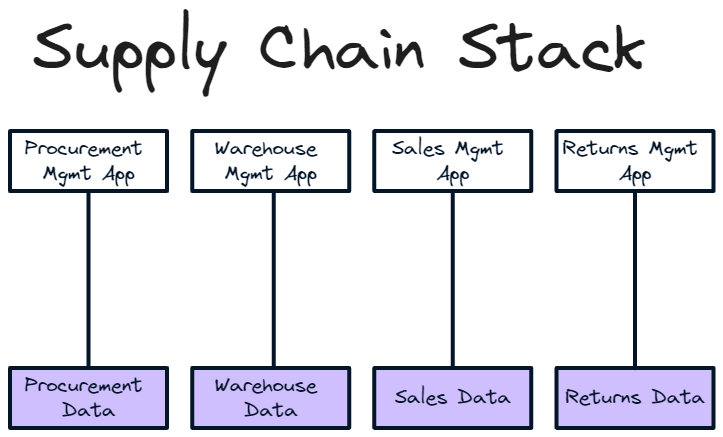
The same is true in other industries and functions. There is no single layer you’re interacting with that:
Gives a complete, connected view across all data sources with no conflicts
Can initiate and run workflows across applications based on that data and changes to it
Provides seamless inter-app communication based on the same underlying data model
Enter data operating systems
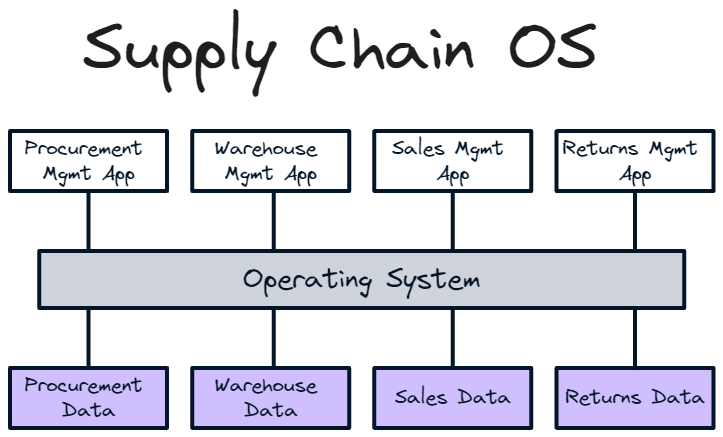
A data OS enables this abstraction. Just as hardware plugged into the operating system and programs sat on top; with data operating systems, the data plugs into the OS and the apps sit on top. When a data source changes, it doesn’t matter, as long as it plugs into the OS. Data operating systems enable users to:
Build apps for the operating system, not the underlying data source, so it didn’t matter what data source is used
Interact directly with the operating system to initiate multiple apps and workflows
Have a coherent view of the underlying data (abstracted away by the operating system) that the apps interact with through the OS, rather than directly
Communicate between apps seamlessly as all apps are working from the same underlying operating system
Not only will this unlock huge innovation as apps no longer have to think about the underlying dataset, and products that build the dataset only have to think about integration with one operating system, rather than hundreds of potential apps, value in the stack will accrue to the operating system. Apps and data sources will compete against each other while the operating system benefits from network effects.
Take a supply chain OS. You could choose from a number of different vendor data sources and vendor data management apps, as long as they were compatible with the OS. This means the data source and the vendor management app will become relatively commoditised as they compete with each other; much like hardware components and apps have become when compared to pre-OS.
Data architecture based on an atomic unit of data
Now, this all seems rather uncontroversial and established. We’ve been talking about operating systems for a few years and things like the Shopify app store enable platform users to choose between different apps since they all use the same underlying set of Shopify data. However, the key difference here is that data operating systems will have a defined data structure based on an atomic unit of record.
Just as atoms are indivisible, the atomic unit of record is the smallest, indivisible unit of data that the system builds up from. For Salesforce and “customer operating systems”, it’s the customer ID; for “workforce operating systems” like Rippling, it’s employee ID; for “finance operating systems”, it may be transaction ID.
The key role the operating system plays will be to define the data standards, data model and atomic unit of data that data sources and apps plug into. A bit like the X86 Instruction Set defines how apps make requests to hardware components within Windows OS, the data OS atomic unit and data model define how apps and data interact.
Most existing OSes are not based on an atomic unit. A lot has been written about vertical OSes, such as Toast (Restaurants), Mindbody (Fitness) & Shopify (DTC retail), & ERPs, such as Oracle; however, I would class these as a bundle of products, rather than an operating system as they contain multiple systems of records and different atomic units. To use my chemistry A-Level knowledge, they’re more like molecules. There will be different atomic units for different parts of the business (eg HR product will have the employee atomic unit; marketing/sales will use the customer as the atomic unit) so really you’re combing atoms into compounds. Additionally, you can’t necessarily swap out a data source within them so if the data source updates, the product has to as well.
The reason a lot of the existing “OS” products typically have a poor experience is because they’re trying to do alchemy. They are trying to combine different atomic units and are compensating for the lack of standardisation and an atomic unit of data across the product. They are often buggy with conflicting data because they trying to turn data sources that have different underlying structures into something that can be combined. If you’re able to break everything down into the atomic unit of data so they can be combined correctly, then you have a much better system.
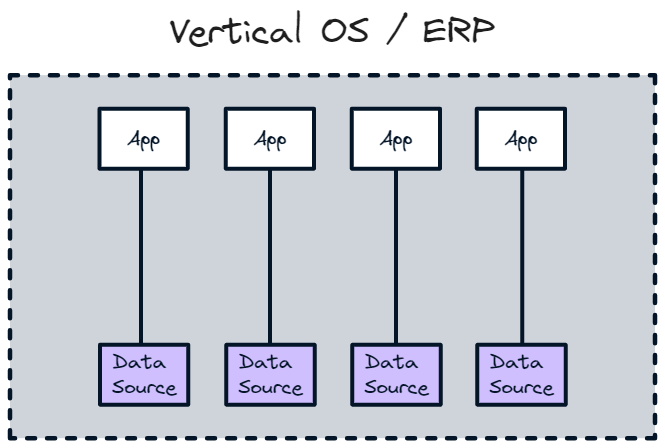
OSes will provide the most value as the systems they map become more complex
Each component of a system will be a separate data source that connects to the data OS layer. We’ll see more and more specialised data sources to map niche components of a system that will link into the overall system map provided by the data OS. The data OS will provide the layer to make it all coherent, cohesive and understandable, compared to flipping between different products for each component of the system, or missing components entirely.
Data OSes will create the most value when used in complex systems with multiple components. They enable users to understand what is going on across a system through a single source of the truth/system of record that is made up of atomic units. The more complex the system, with the more components involved, the greater the value of having a unified OS layer. I believe we’ll start to see more data OSes appearing in more complex systems over the next few years.
We already have a few data OSes in simple systems. Salesforce is the obvious example and their market cap demonstrates the value that accrues to the OS layer. However, this is just one example of an OS. There is a huge opportunity outside of customer OSes at the department level (e.g. supply chain OS, finance OS) and at the industry level (e.g. energy system, financial system). Data OSes apply in any instance where a system needs mapping and workflows and decisions are initiated off the back of that information. If you need to understand what is going on across multiple components, a data OS has potential. We’ve started on the basics and now will see data OSes move into more complex systems and systems of systems, unlocking and accruing more and more value.
Building the operating system
As with building hardware operating systems, there are different approaches that we can use with data OSes. I’m not sure which is best and I suspect the strategy a new data OS chooses will likely change based on industry and what data standards are required to build the unified atomic data later. Ultimately data OSes will choose a mix of approaches, similar to the way Salesforce enables you to define the customer ID via their own product or via an integration. However, with both, the key first step will be defining the data model and building the integrations/products that fill it up, before moving on to apps. The OS is useless without the data - doing anything other than building the data set first would be like building an app for a new Windows replacement that didn’t yet have a way of interacting with a processor or RAM.
MacOS approach
Apple deeply integrates their software and hardware. While they don’t build all components in-house, they work closely with suppliers to build out deep integrations with their OS and create what they believe is a better customer experience using best-in-class components. They went for depth of integration over breadth.
Rippling are taking this approach by building out their own suite of products as they build their HR/employee OS. A start-up may start with a wedge product(s) that captures the data and builds the data model within the OS before expanding into building apps on top of and based on the data. This approach would probably be used if existing data sources couldn’t provide the data to the standards and atomic unit you need.
Windows approach
Windows is relatively hardware agnostic and went for breadth over depth of integration with hardware components. A data OS could mimic this approach by building integrations with a broad set of existing data sources and apps, rather than building in-house, focusing instead on the data architecture.
Palantir is sort of doing this by integrating with their clients’ existing data sources but they are currently building custom OSes for each client. This shows the need for data standards and atomic units when building the data OS so you can standardise and replicate integrations for each deployment. This is also the reason Palantir are so expensive - they are currently custom-integrating everything. Additionally, they are trying to unify lots of different systems that may not have an atomic unit (or they may not define the atomic unit) given the sheer size of their customers.
Linux approach
There is a third approach a startup could take. There are a few companies like Plaid and TransactionLink that are building platforms to integrate 3rd party products under a single API. They can be used to build and map a workflow that is custom to each deployment of the platform, like Linux is custom to each OS deployment.
Using these products is the equivalent of collating all the data sources and apps on a single platform. It is then not that much harder to make the leap to an operating system, unifying the 3rd party provider records and consolidating everything under a single system of record. You can then build new apps on top that are unlocked by having this unified system.
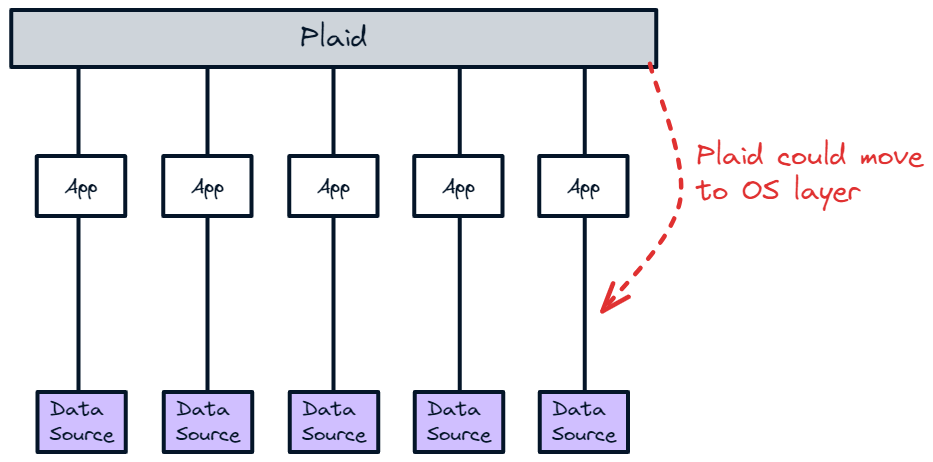
Ultimately data OSes need to build a unified atomic data layer with all components of the system feeding in data at the atomic level. The strategy a startup takes will depend on the ability to create this data layer using the existing data sources or whether they will have to build their own. All strategies enable apps to be independent of data sources because they standardize the inputs but I believe the winners will be the ones that enable the most accurate and granular mapping of the system. As data OSes move from smaller systems like customer and employee data and into more complex functions such as supply chains, finance and even up to the broader energy and financial system, we’ll see some huge companies evolve. To enable this, data OSes will need to think carefully about their approach as they define the atomic unit of their data architecture and choose whether to go broad or deep with their integrations.
Big thanks to Tom, Chelsea, Cesca and Emma for their help and suggestions on this post